PDFからテキストを抽出する方法|文字起こし・画像PDFのテキスト化にも対応
PDFから文字を抽出しようとして、「コピーできない」「文字が選択できない」と感じたことはありませんか?
特にスキャンされたPDFや画像PDFでは、通常の方法ではテキスト化できず、OCRを使ったPDF文字起こしが必要になります。
この記事では、PDFテキスト抽出の仕組みから、PDFをテキストに変換できない場合の原因と対処法、無料で試せるOCRツールまで詳しく紹介します。
︎Part1. PDFテキスト抽出とは?
PDFテキスト抽出とは、PDFファイルに含まれるテキストデータを取り出すことを指します。多くの場合、テキストを選択してコピーするだけで簡単に行えます。しかし、PDFファイルには「テキスト型」と「画像型(スキャンPDF)」の2種類が存在します。
PDF内の文字をコピー&ペーストする仕組み:
PDF内の文字をコピー&ペーストする仕組みはPDF閲覧ソフトやPDF編集ソフトが、PDF内のテキストを読み取り、右クリックやショートカットキーでコピー&ペーストが可能です。
スキャンPDF(画像PDF)との違い:
スキャンされたPDFは、文字が画像として保存されているため、通常の方法ではテキスト抽出ができません。ここで必要となるのが「OCR(光学文字認識)」技術です。
︎Part2. PDF文字起こしの場合と簡単なやり方
1.テキスト抽出可能なPDFの場合
テキスト型PDFであれば、Google Chromeなどのブラウザを利用して、直接テキストを選択・コピーできます。簡単なPDFテキスト抽出無料方法としても活用可能です。
テキスト形式のPDFファイルの場合、Google ChromeやMicrosoft Edgeなどの一般的なブラウザを使用すれば、特別なソフトウェアをインストールする必要なく、直接テキストを選択してコピーすることが可能です。この方法は操作が簡単で、完全に無料で利用できるため、PDFからテキストを無料で抽出するの手軽な方法となっています。
注意点:
- レイアウトが崩れる
- フォントやエンコードの影響で文字化けすることがある。
- PDFにコピー制限がかかっている場合、操作できない。
2.テキストを抽出できないPDF(画像PDF)の場合
しかし、すべてのPDFがテキストを簡単にコピーできるわけではありません。中には、スキャン画像として保存された「画像PDF」もあり、こうしたファイルではテキストの選択やコピーができません。このような場合には、OCR(光学文字認識)技術を使った対応が必要になります。
ただし、OCRの精度は元のスキャン画像の品質に大きく左右されるため、無料のツールでは十分な結果が得られないこともあります。
そこで活躍するのが、Tenorshare PDNobです。AI技術を活用し、日本語にも対応した高精度な文字認識が可能です。ぼやけたスキャン画像やコピー制限付きPDFでも、画面上の文字を直接抽出できるスクリーンOCR機能により、PDFファイルからテキストを抽出できない場面でも柔軟に対応できます。
操作手順
公式サイトから Tenorshare PDNob をダウンロードし、インストール。




ソフトを起動し、「PDFを開く」をクリックし、抽出したいPDFファイルをアップロード。

ツールバーから「ホーム」・「OCR」をクリックし、スキャンオプション、ページ範囲や言語認識を選択します。
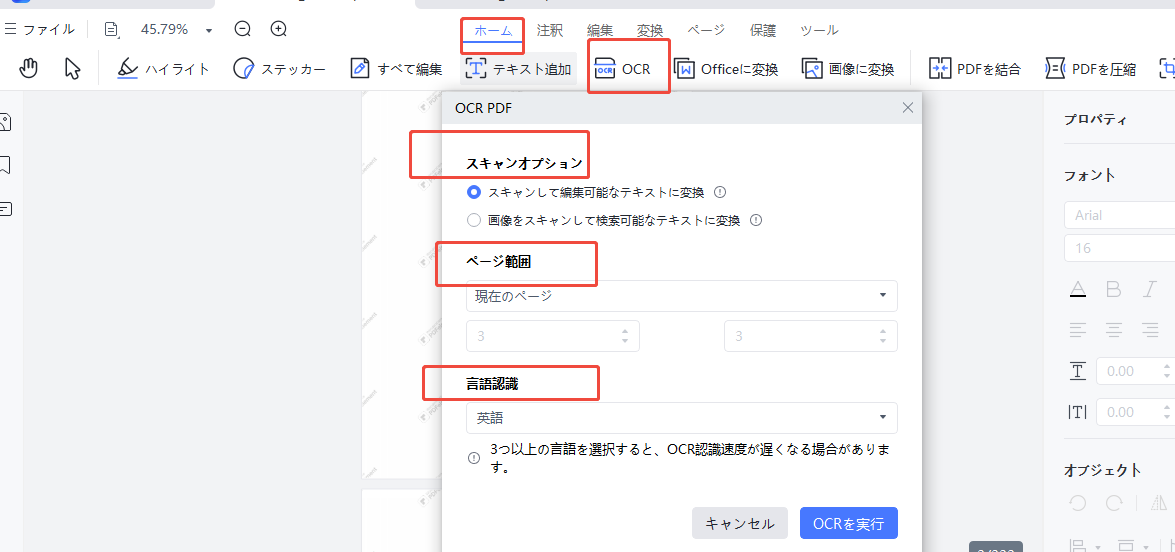
そして「OCRを実行」をクリック、PDFテキスト抽出が開始。

PDFテキスト抽出が終わったら、名前を付けて保存して完了。



おすすめ理由:
- 表や画像を含むPDFはテキスト抽出後に乱れることはありません。
- PDFはテキスト抽出後の編集をサポートします。
- テキスト抽出は16言語の認識をサポートします。
- 使用時にインターネットに接続する必要がなく、データは長期間保存できます。
︎Part3. OCRを使ったPDFのテキスト化できるツール4選
OCRを利用することで、スキャンPDFなど画像ベースのファイルでもPDFをテキストに変換することが可能になります。以下は、無料で使えるOCRツールの例です。
1.Smallpdf OCR:
シンプルな操作性で初心者にもおすすめ。PDFをアップロードするだけで自動的に文字を認識し、テキスト形式でダウンロード可能。
主な機能:
- スキャンPDFや画像PDFをOCR処理でテキストデータに変換可能(Pro版)
- WordやTXT、Excelなどへの変換(pdf をテキストに変換/pdf テキスト化)
- パスワード解除やPDF編集(圧縮・分割・回転)にも対応
- ブラウザベースでインストール不要
メリット:
- 操作が非常にシンプルで、PDF初心者にも扱いやすい
- ファイルをアップロードするだけで自動OCR開始
- WordやTXT、Excelなど複数形式でのテキスト抽出が可能
- 高精度OCRで文字認識率が高い
注意点
- OCR機能は無料プランでは使用不可、有料版が必要
- テキスト抽出の際、日本語OCRを手動で選ばないと文字化けしたテキストが生成される場合が可能。
- 表形式データの抽出は精度が落ちる可能性(pdf テキスト抽出 エクセルでは整形の手間あり)
- レイアウトが複雑なPDFでは改行やスペースが不自然になることも
2.PDF Candy 抽出機能:
多機能なオンラインPDFツールのひとつで、OCR機能も搭載。抽出後は「PDFテキスト抽出 エクセル」への変換も可能です。

主な機能:
- スキャンPDFからOCRで文字起こしが可能
- 出力形式はTXT・Word・PDFなど多様
- 表形式PDFからExcel形式への抽出も対応
メリット:
- インストール不要、ブラウザのみで全機能利用可能
- 一括バッチ処理対応で、複数PDFをまとめてテキスト化可能
- 高精度OCR搭載で、文字の認識力も安定
- PDF テキスト抽出 無料としても十分実用的
注意点
- 無料利用では時間あたりのファイル数やファイルサイズに制限あり
- 日本語OCRに精度のばらつきがあるため、抽出後に校正が必要
- 文字だけでなく画像や表が多いPDFでは抽出後の整形が必要
- 一部レイアウトが崩れることがあり、文章構造の再整理が必要
3.iLovePDF OCR:
操作画面がわかりやすく、多言語対応もあり。PDF内の画像文字を正確に読み取ります。

主な機能:
- スキャンされたPDFや画像PDFテキスト抽出に対応
- PDFからTXTまたは検索可能なPDFへ変換(pdf をテキストに変換)
- PDFの結合・分割・保護解除などの機能も統合
メリット:
- Google DriveやDropboxとの連携がスムーズで、クラウド保存に最適
- スピードが速く、大容量PDFでも短時間で処理可能
- UIが直感的で、初心者にも扱いやすい
- セキュリティ対策として、処理後ファイルは短時間で自動削除
注意点
- OCR機能は有料アカウントでのみ利用可能(無料版では制限)
- 表や段組みのあるPDFでは構造が崩れることがある
- 抽出結果を事前プレビューできないため、認識ミスの確認が手動になる
- 画質の悪いPDFでは誤認識が多く、抽出後に手作業で修正が必要
4.Googleドキュメント:
Googleアカウントがあれば誰でも使える無料OCR。PDFをドライブにアップロードし、Googleドキュメントで開くことで自動的に文字認識が実行されます。

主な機能:
- GoogleドライブにアップロードしたPDFをGoogleドキュメントで開くと、OCRによって自動的にテキスト抽出(pdf テキスト抽出 無料)
- テキスト編集・保存・翻訳まで可能(pdf 文字 起こし/pdf テキスト化)
- Google Workspace内での共有・共同編集にも対応
メリット:
- 完全無料、Googleアカウントがあればすぐに利用可能
- 他Googleサービス(翻訳、共有、コメントなど)との連携がスムーズ
- クラウド上での作業なので、端末容量に依存せず作業可能
- 編集・保存・テキスト検索が全てオンライン上で完結する
注意点
- レイアウト保持は難しく、表・画像・段組みなどの再現が不完全
- 低画質スキャンPDFや手書き文字には弱く、文字の認識精度が下がる
- 縦書きや日本語特殊文字の誤認識率が高め
- テキスト抽出はあくまでGoogleドキュメント内で編集可能な形式に変換されるだけで、PDFそのものには反映されない
︎Part4. PDFテキスト抽出できない原因と解決策
PDFファイルによっては、思うようにテキストが抽出できないケースがあります。その原因と対策を以下に整理します。
原因①:PDFが画像化されている(スキャンPDF)
スキャンされたPDFは画像として保存されているため、文字を選択・コピーすることができません。この場合、OCR(光学文字認識)による文字起こしが必要になります。
対策:
日本語OCRに対応したPDNobを使えば、スキャンPDFや画質が低下した文書でも文字を正確に認識し、画面上のテキストを直接抽出できます。
スキャンPDFからテキストを抽出することはできますか?
はい、スキャンPDFでもOCR機能を使えばテキスト抽出が可能です。日本語対応のOCRツールを利用することで、画像化されたPDFをテキスト化できます。
原因②:PDFがパスワードやコピー制限されている(暗号化PDF)
コピーや印刷を制限するため、パスワード保護されたPDFではテキスト抽出ができない場合があります。
- パスワードを知っている場合:PDNobで該当のPDFを開き、パスワードを入力して解除した後、スクリーンOCR機能を使って画面上のテキストを抽出できます。これにより、コピー制限がかかったPDFでも文字情報を取得することが可能です。
- パスワードを知らない場合:PDFファイルにパスワード保護やコピー制限がかかっており、テキスト抽出や印刷ができない場合は、専門の解除ツールであるPassFab for PDFやPDF2Go Unlock PDFなどの使用が有効です。PDFをアップロードしてパスワードを解除できます。
コピー制限されたPDFから文字を取り出す方法は?
パスワードを解除したうえでOCRを使用することで、コピー制限があるPDFでもテキスト抽出が可能になります。
注意事項:
PassFab for PDFを含むすべての解除ツールの使用は、合法的な目的に限って行ってください。著作権や契約に反する利用は法律で禁止されています。使用は自己責任で行ってください。
︎まとめ
PDFからテキストを抽出する作業は、PDFの種類によって方法が異なります。 通常のテキスト型PDFであれば、ブラウザやPDF閲覧ソフトで簡単にコピーできますが、スキャンPDFや画像PDFではOCRを使った文字起こしが不可欠になります。
無料のOCRツールでもテキスト化は可能ですが、日本語対応やレイアウト保持には限界があり、精度の差が出ることがあります。そのため、日本語OCR対応かつ高精度な文字抽出ができるツールを選ぶことが作業効率を左右します。
Tenorshare PDNobは、画像PDFでも日本語テキストを高精度で認識し、画面上の文字を直接抽出・編集可能な形式にできます。まだ抽出できないPDFに悩んでいる方は、まずはPDNobの無料体験版で実際の文字抽出精度を確認してみてください。OCR精度や操作性を実感することで、日常作業の生産性が大きく向上するはずです。

- スマートAI: PDFの読み取りから要約、インサイト抽出までを従来より300倍の速さで実現。
- フォーマット変換: PDFをWord、Excel、PowerPoint、画像、PDF/A、テキスト、EPUBなど、30種類以上の形式に変換可能。
- PDF編集: テキスト、画像、透かし、リンク、背景の編集に加え、PDFの結合や保護など100以上の編集機能を搭載。
- PDF注釈: ステッカー、ハイライト、アンダーライン、図形、スタンプなど、200種類以上の多彩な注釈ツールを提供。
- OCR機能: スキャンしたPDFを99%の精度で、編集や検索が可能なデータに変換。


(0 票、平均: 5.0 out of 5 )
(クリックしてこの記事へコメント)